|
Опрос
|
реклама
Быстрый переход
64 пикселя за 20 минут: на 40-летнем компьютере Commodore 64 запустили ИИ-генератор изображений
10.05.2024 [17:58],
Павел Котов
В августе 1982 года вышел компьютер Commodore 64, которому было суждено стать одним из самых продаваемых ПК всех времён. Как оказалось, оборудование той эпохи и может справляться и с современными алгоритмами искусственного интеллекта — конечно, с некоторыми оговорками. 
Источник изображения: github.com/nickbild Энтузиаст Ник Бильд (Nick Bild) разработал для Commodore 64 систему генеративного ИИ, способную создавать изображения размером 8 × 8 пикселей, которые затем преобразуются в картинки 64 × 64 точки. Эти изображения призваны служить источником вдохновения при разработке концепций игрового дизайна. Как оказалось, современную модель генеративного ИИ действительно можно запускать на таком старом оборудовании. На выполнение 94 итерации для построения окончательного изображения у Commodore 64 ушли 20 минут — и это, пожалуй, совсем неплохо, учитывая возраст компьютера. О проектах уровня OpenAI речи, конечно, не идёт, но и «вероятностный алгоритм PCA», запущенный на 40-летней машине, в реальности был обучен на современном компьютере. Таким образом, хотя модель и по-честному работала на Commodore 64, для её запуска всё равно оказался необходим современный ПК. В США разработан законопроект, который позволит ограничивать экспорт моделей ИИ
10.05.2024 [16:55],
Павел Котов
Американские парламентарии разработали законопроект, который облегчит администрации президента установление экспортного контроля над моделями искусственного интеллекта — это очередная попытка США защитить свои технологии от посягательств считающихся недружественными стран. 
Источник изображения: Brian Penny / pixabay.com Документ подготовлен представителями обеих крупнейших политических партий США — она также предоставит Министерству торговли полномочия запрещать американским специалистам сотрудничество с иностранцами при разработке систем ИИ, если те представляют угрозу для национальной безопасности страны. Законопроект призван защитить любые будущие нормы экспортного контроля в отношении ИИ от юридических проблем — в его разработке участвовали чиновники администрации президента. В политической среде США растут опасения, что считающиеся недружественными страны будут использовать американские модели ИИ для проведения кибератак или создания мощного биологического оружия. В минувшую среду стало известно, что США готовятся открыть новый фронт санкционной войны с Россией и Китаем и начали изучать план по введению экспортного контроля в отношении передовых моделей ИИ. В соответствии с действующим законодательством курирующему экспортную политику Минторгу США значительно сложнее контролировать экспорт открытых моделей ИИ, которые можно свободно загрузить. Принятие закона устранит препятствия на пути регулирования экспорта открытых моделей ИИ — такие препятствия накладывает действующий «Закон о чрезвычайных международных экономических полномочиях», — а Минторг получит особые полномочия по регулированию систем ИИ. В марте китайские государственные СМИ распространили заявление Пекинской академии искусственного интеллекта, согласно которому большинство моделей ИИ в стране были созданы с использованием открытых моделей Meta✴ Llama, и это большая проблема для китайских разработчиков. В ноябре считавшийся перспективным китайский стартап 01.AI, учреждённый бывшим топ-менеджером Google Ли Кай-фу (Lee Kai-fu) подвергся резкой критике, когда инженеры в области ИИ обнаружили, что разработанная стартапом модель также была построена на основе Llama. Новая статья: Практикум по ИИ-рисованию, часть восьмая: больше жизни!
10.05.2024 [00:03],
3DNews Team
Данные берутся из публикации Практикум по ИИ-рисованию, часть восьмая: больше жизни! McAfee продемонстрировала детектор звуковых дипфейков
09.05.2024 [15:08],
Павел Котов
На мероприятии RSA Conference компания McAfee продемонстрировала систему Deepfake Detector, работа над которой ведётся при участии Intel. Система, первоначально называвшаяся Project Mockingbird, предназначена для обнаружения звуковых дипфейков — аудиоподделок, созданных при помощи искусственного интеллекта. 
Источник изображения: S. Keller / pixabay.com Технический директор McAfee Стив Гробман (Steve Grobman) показал работу Deepfake Detector на примере двух видеороликов — показ видео сопровождается информацией от ИИ-детектора, которая выводится в строке состояния. При запуске видеоролика, не подвергавшегося обработке, система показала нулевую вероятность подделки. Далее было запущено явно фейковое видео, на которое система сразу отреагировала показателем в 60 %, и по мере просмотра вероятность выросла до 95 %. С момента первой демонстрации на CES 2024 инженеры McAfee оптимизировали систему для работы с ИИ-ускорителями Intel NPU на чипах Meteor Lake, что позволило увеличить производительность на 300 %. Можно запускать несколько процессов Deepfake Detector для одновременного анализа нескольких видеороликов; хотя и видеозаписями возможности системы не ограничиваются — она может анализировать звук любого приложения в системе. А локальный режим её работы вместо запуска из облака означает высокую конфиденциальность — анализируемые данные не покидают компьютера. Авторы проекта преднамеренно ограничились работой со звуком: специалисты McAfee по борьбе с угрозами обнаружили, что во многих публикуемых мошенниками видеороликах используется настоящее видео с поддельным звуком. Фальшивый звук сопровождает и поддельное видео, а значит, постоянной величиной чаще всего оказывается подделка аудио. Сейчас компания работает над адаптацией технологии для потребителей — для этого управление программой будет необходимо сделать предельно простым и понятным. Google представила мощную нейросеть AlphaFold 3 для предсказания структуры белков — её может опробовать каждый
09.05.2024 [12:38],
Павел Котов
Подразделение Google DeepMind представило новую версию модели искусственного интеллекта AlphaFold, которая предсказывает форму и поведение белков. AlphaFold 3 отличается не только более высокой точностью — теперь система предсказывает взаимодействие белков с другими биологическими молекулами; кроме того, её ограниченная версия теперь бесплатно доступна в формате веб-приложения. 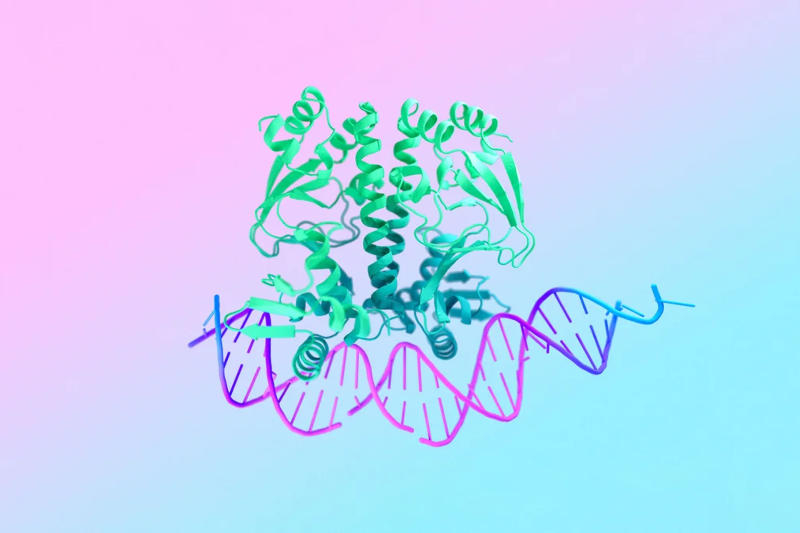
Источник изображения: blog.google С выхода первой нейросети AlphaFold в 2018 году она стала ведущим методом прогнозирования структуры белков на основе последовательностей аминокислот, из которых они состоят. Понимание структуры и основ взаимодействия белков лежит в основе почти всей биологии. Классические методы моделирования белков имеют значительные ограничения: даже зная форму, которую примет последовательность аминокислот, нельзя сказать наперёд, с какими другими молекулами она будет связываться и как. И если необходимо достичь какой-то практической цели, требуется кропотливая работа по моделированию и тестированию — ранее на это уходили несколько дней, а иногда даже недель и месяцев. AlphaFold решает эту задачу, предсказывая вероятную форму молекулы белка по заданной последовательности аминокислот, указывая, с какими другими белками она сможет взаимодействовать. Особенность новой AlphaFold 3 состоит в её способности предсказывать взаимодействие белков с другими биологическими молекулами, в том числе с цепочками ДНК и РНК, а также необходимыми для этого ионами. Большой проблемой AlphaFold, как и других инструментов на основе ИИ, является сложность в их развёртывании. Поэтому в Google DeepMind запустили бесплатное веб-приложение AlphaFold Server — оно доступно для некоммерческого использования. Платформа достаточно проста в работе: осуществив вход с учётной записью Google, можно ввести несколько последовательностей и категорий, после чего она выдаст результат в виде трёхмерной молекулы, окрашенной в цвет, который отражает уверенность модели в своей правоте. На вопрос о том, есть ли существенная разница между общедоступной версией модели и той, что используется внутри компании, глава подразделения Google DeepMind Демис Хассабис (Demis Hassabis) заверил, что «мы сделали доступными большинство функций новой модели», но подробностей не привёл. Через год сегодняшний ChatGPT будет выглядеть смехотворно плохо, заявил директор OpenAI
08.05.2024 [13:51],
Дмитрий Федоров
Брэд Лайткап (Brad Lightcap), главный операционный директор OpenAI, рассказал на Глобальной конференции в Институте Милкена о будущем компании и её планах на следующие 6–12 месяцев. По его мнению, нынешние системы искусственного интеллекта (ИИ), такие как ChatGPT, являются «смехотворно плохими» по сравнению с тем, что ждёт человечество впереди. Он подчеркнул, что будущие версии ИИ будут настолько продвинутыми, что изменят саму суть взаимодействия с пользователями. 
Источник изображения: JuliusH / Pixabay Лайткап описал нынешнюю версию ChatGPT как начальный этап в эволюции ИИ, предназначенного для выполнения простых задач. «Я думаю, что через год мы оглянемся назад и поймём, насколько несовершенными они были», — заявил Лайткап, когда его спросили о бизнесе OpenAI через 6–12 месяцев. В перспективе он предвидит эволюцию ИИ в направлении более сложных задач, где ИИ станет отличным напарником, способным на равных общаться с людьми, как друг или коллега. Кроме технологических аспектов Лайткап прокомментировал социальные последствия развития ИИ. Он опроверг мнение о том, что развитие ИИ приведёт к массовым увольнениям людей, утверждая, что новые ИИ-системы наоборот спровоцируют спрос на ещё не существующие вакансии. По его мнению, экономика станет более разнообразной и устойчивой, а рынок труда адаптируется к технологическим изменениям. В свете этих заявлений интересно, что генеральный директор OpenAI Сэм Альтман (Sam Altman) также высказывался о будущем ChatGPT на семинаре в Стэнфордском университете, назвав GPT-4 самой глупой моделью, с которой людям придётся работать когда-либо в будущем. Такие заявления вероятно намекают на то, что будущие обновления ChatGPT станут переломными и приведут к значительному улучшению функциональности продуктов OpenAI. OpenAI позволит правообладателям запретить использование контента для обучения ИИ
08.05.2024 [12:34],
Павел Котов
OpenAI сообщила, что разрабатывает инструмент под названием Media Manager, который позволит создателям и владельцам контента отметить свои работы для компании и указать, как можно ли их включать в массив данных для исследований и обучения ИИ, или же нельзя. 
Источник изображения: Growtika / unsplash.com Инженеры OpenAI намереваются разработать этот инструмент к 2025 году. Сейчас компания сотрудничает с «создателями контента, правообладателями и регуляторами» над выработкой стандарта. «Создание первого в своём роде инструмента, который поможет нам идентифицировать текст, аудио и видео, защищённые авторским правом, в нескольких источниках и отразить предпочтения создателей, потребует передовых исследований в области машинного обучения. Со временем мы планируем внедрить дополнительные возможности и функции», — сообщила OpenAI в своём блоге. Media Manager, вероятно, станет ответом компании на критику в отношении её подхода к разработке искусственного интеллекта. Она в значительной степени использует общедоступные данные из интернета, но совсем недавно несколько крупных американских изданий подали на OpenAI в суд за нарушение прав интеллектуальной собственности: по версии истцов, компания украла содержимое их статей для обучения моделей генеративного ИИ, которые затем коммерциализировались без компенсации и упоминания исходных публикаций. OpenAI считает, что невозможно создавать полезные модели ИИ без защищённых авторским правом материалов. Но в стремлении унять критику и защититься от вероятных исков компания предприняла несколько шагов, чтобы пойти навстречу создателям контента. В прошлом году она позволила художникам удалять свои работы из наборов обучающих данных для генераторов изображений, а также ввела директиву для файла robots.txt, которая запрещает её поисковому роботу копировать содержимое сайтов для дальнейшего обучения ИИ. OpenAI продолжает заключать соглашения с крупными правообладателями на предмет использования их материалов. OpenAI научилась распознавать сгенерированные своим ИИ изображения, но не без ошибок
08.05.2024 [10:19],
Дмитрий Федоров
OpenAI объявила о начале разработки новых методов определения контента, созданного искусственным интеллектом (ИИ). Среди них — новый классификатор изображений, который определяет, было ли изображение сгенерировано ИИ, а также устойчивый к взлому водяной знак, способный маркировать аудиоконтент незаметными сигналами. 
Источник изображения: Placidplace / Pixabay Новый классификатор изображений способен с точностью до 98 % определять, было ли изображение создано ИИ-генератором изображений DALL-E 3. Компания утверждает, что их классификатор работает, даже если изображение было обрезано, сжато или была изменена его насыщенность. В то же время эффективность этой разработки OpenAI в распознавании контента, созданного другими ИИ-моделями, такими как Midjourney, значительно ниже — от 5 до 10 %. Также OpenAI ввела водяные знаки для аудиоконтента, созданного с помощью своей платформы преобразования текста в речь Voice Engine, находящейся на стадии предварительного тестирования. Эти водяные знаки содержат информацию о создателе и методах создания контента, что значительно упрощает процесс проверки их подлинности. OpenAI активно участвует в работе Коалиции по происхождению и аутентичности контента (C2PA), в состав которой также входят такие компании, как Microsoft и Adobe. В этом месяце компания присоединилась к руководящему комитету C2PA, подчеркивая свою роль в разработке стандартов прозрачности и подлинности цифрового контента. Для этих целей OpenAI интегрировала в метаданные изображений так называемые учётные данные контента от C2PA. Эти учётные данные, фактически являясь водяными знаками, включают информацию о владельце изображения и способах его создания. OpenAI уже много лет работает над обнаружением ИИ-контента, однако в 2023 году компании пришлось прекратить работу программы, определяющей текст, сгенерированный ИИ, из-за её низкой точности. Разработка классификатора изображений и водяного знака для аудиоконтента продолжается. В OpenAI подчёркивают, что для оценки эффективности этих инструментов крайне важно получить отзывы пользователей. Исследователи и представители некоммерческих журналистских организаций имеют возможность протестировать классификатор изображений на платформе доступа к исследованиям OpenAI. Microsoft создала секретный генеративный ИИ для спецслужб США — он полностью изолирован от интернета
07.05.2024 [20:03],
Сергей Сурабекянц
Корпорация Microsoft запустила предназначенную для спецслужб США модель генеративного искусственного интеллекта на суперкомпьютере, полностью изолированном от интернета. Теперь Малдер и Скалли смогут безопасно использовать современные технологии для анализа сверхсекретной информации. 
Источник изображений: unsplash.com По словам представителя Microsoft, впервые большая языковая модель генеративного ИИ на основе GPT-4 полностью отделена от интернета. Большинство подобных моделей, включая ChatGPT от OpenAI, полагаются на облачные сервисы для обучения и определения закономерностей, но Microsoft хотела предоставить разведывательному сообществу США «по-настоящему безопасную систему». Разведывательные службы всех стран рассчитывают, что генеративный ИИ поможет в анализе быстро растущих объёмов ежедневно генерируемой секретной информации, но им необходимо сбалансировать обращение к большим языковым моделям с риском утечки или взлома. В прошлом году ЦРУ запустило службу, подобную ChatGPT, для работы с несекретными документами, но спецслужбам требовалось обрабатывать гораздо более конфиденциальные данные. «Идёт гонка по внедрению генеративного ИИ в разведывательные данные, — заявила помощник директора Центра транснациональных и технологических миссий ЦРУ Шитал Патель (Sheetal Patel). — Первая страна, которая будет использовать генеративный ИИ, выиграет эту гонку. И я хочу, чтобы это были мы».  Microsoft потратила 18 месяцев на разработку и внедрение системы, включая капитальные доработки существующего суперкомпьютера в Айове. Представленная модель GPT4 является статической, то есть она может только анализировать информацию, но не обучаться на этих данных. Таким образом, правительство может сохранить свою модель «чистой» и предотвратить утечку секретной информации. Прогнозируется, что доступ к системе получат около 10 000 сотрудников со специальным допуском. ИИ научил робопса балансировать на шаре — он тренирует роботов эффективнее, чем люди
07.05.2024 [12:23],
Павел Котов
Группа учёных Пенсильванского университета разработала систему DrEureka, предназначенную для обучения роботов с использованием больших языковых моделей искусственного интеллекта вроде OpenAI GPT-4. Как оказалось, это более эффективный способ, чем последовательность заданий в реальном мире, но он требует особого внимания со стороны человека из-за особенностей «мышления» ИИ. 
Источник изображения: eureka-research.github.io Платформа DrEureka (Domain Randomization Eureka) подтвердила свою работоспособность на примере робота Unitree Go1 — четвероногой машины с открытым исходным кодом. Она предполагает обучение робота в симулированной среде, используя рандомизацию основных переменных: показатели трения, массы, демпфирования, смещения центра тяжести и других параметров. На основе нескольких пользовательских запросов ИИ сгенерировал код, описывающий систему вознаграждений и штрафов для обучения робота в виртуальной среде. По итогам каждой симуляции ИИ анализирует, насколько хорошо виртуальный робот справился с очередной задачей, и как её выполнение можно улучшить. Важно, что нейросеть способна быстро генерировать сценарии в больших объёмах и запускать их выполнение одновременно. ИИ создаёт задачи с максимальными и минимальными значениями параметров на точках отказа или поломки механизма, достижение или превышение которых влечёт снижение балла за прохождение учебного сценария. Авторы исследования отмечают, что для корректного написания кода ИИ требуются дополнительные инструкции по безопасности, в противном случае нейросеть при моделировании начинает «жульничать» в стремлении к максимальной производительности, что в реальном мире может привести к перегреву двигателей или повреждению конечностей робота. В одном из таких неестественных сценариев виртуальный робот «обнаружил» что способен передвигаться быстрее, если отключит одну из ног и начнёт передвигаться на трёх. Исследователи поручили ИИ соблюдать особую осторожность с учётом того, что обученный робот будет проходить испытания и реальном мире, поэтому нейросеть создала дополнительные функции безопасности для таких аспектов как плавность движений, горизонтальная ориентация и высота положения туловища, а также учёт величины крутящего момента для электродвигателей — он не должен превышать заданных значений. В результате система DrEureka справилась с обучением робота лучше, чем человек: машина показала 34-процентный прирост в скорости движения и 20-процентное увеличение расстояния, преодолеваемого по пересечённой местности. Такой результат исследователи объяснили разницей в подходах. При обучении задаче человек разбивает её на несколько этапов и находит решение по каждому из них, тогда как GPT проводит обучение всему сразу, и на это человек явно не способен. В результате система DrEureka позволила перейти от симуляции напрямую к работе в реальном мире. Авторы проекта утверждают, что могли бы дополнительно повысить эффективность работы платформы, если бы сумели предоставить ИИ обратную связь из реального мира — для этого нейросети потребовалось бы изучать видеозаписи испытаний, не ограничиваясь анализом ошибок в системных журналах робота. Среднему человеку требуются до 1,5 лет, чтобы научиться ходить, и лишь немногие способны передвигаться верхом на мяче для йоги. Обученный DrEureka робот эффективно справляется и с этой задачей. Opera добавила ИИ-функцию краткой сводки веб-страниц для Android
07.05.2024 [06:27],
Анжелла Марина
Браузер Opera для Android получил удобный ИИ-инструмент для быстрого ознакомления с содержанием веб-страниц. Новая функция генерирует краткое резюме длинных статей и сообщений, позволяя экономить время на понимание темы и поиск ключевых деталей. Для использования функции «Сводка» нужно обновить Opera для Android до последней версии и войти в учётную запись. 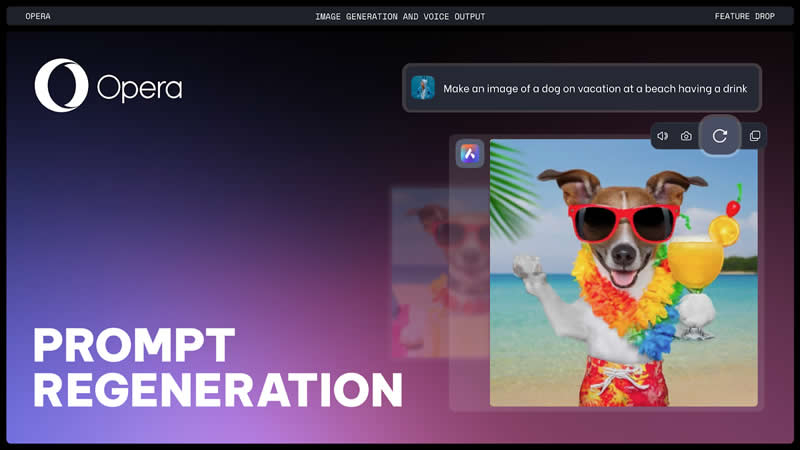
Источник изображения: Opera Инструмент реферирования текста основан на встроенном в Opera помощнике искусственного интеллекта Aria. Пользователю достаточно открыть любую текстовую страницу в Opera, нажать на три точки в правом верхнем углу и выбрать пункт «Сводка» (Summarize) рядом с иконкой Aria. После этого откроется диалог, в котором будет представлено краткое резюме статьи, обычно умещающееся на одном экране. Такое резюме помогает быстро понять суть, выделить основные моменты и решить, стоит ли тратить время на полное прочтение. Это действительно удобно, когда нужно быстро ознакомиться с большим количеством информации, найденной в интернете. Также помощник теперь может зачитывать текстовые ответы вслух. Напомним, помощник искусственного интеллекта Aria был интегрирован в браузер Opera около года назад. Он работает как чат-бот, отвечая на вопросы пользователей и является альтернативой традиционному поиску в интернете. А совсем недавно в Aria была добавлена возможность генерировать изображения на основе текстовых запросов с использованием технологии Imagen 2 компании Google. Разработчики постоянно расширяют функциональность Aria с помощью специальной программы обновлений AI Feature Drops, чтобы пользователи получали все последние улучшения для комфортного использования всех опций интеллектуального браузера. YouTube протестирует на платных подписчиках перемотку видео сразу на самое интересное место
06.05.2024 [11:48],
Дмитрий Федоров
YouTube тестирует новую функцию, которая позволяет пользователю быстро переключаться на самый интересный момент просматриваемого ролика. Для этого используются данные о просмотрах видео и искусственный интеллект (ИИ). Эксперимент продлится до 1 июня, и его результаты могут оказать значительное влияние на общую стратегию сервиса. 
Источник изображения: muhammadsaqii786 / Pixabay YouTube начал тестировать упомянутую функцию в марте текущего года с участием небольшой группы пользователей, но теперь сделал её доступной для подписчиков YouTube Premium. Принцип работы довольно прост: когда пользователь дважды нажимает, чтобы перемотать видео вперёд, появляется кнопка, которая перемещает его к тому месту, до которого обычно перематывают большинство зрителей. Для определения наиболее просматриваемых эпизодов функция использует ИИ и данные о просмотрах видео. Для получения доступа к функции необходимо быть подписчиком YouTube Premium и также включить экспериментальные функции сервиса. В настоящее время нововведение доступно только в США для приложения YouTube на Android и только для видео на английском языке, по которым есть достаточно данных, чтобы определить любимые моменты зрителей. Согласно информации на сайте YouTube, тестирование функции продлится до 1 июня. После этого, предположительно, будет собрана обратная связь от пользователей, и на основе неё будет принято решение о более широком внедрении функции. Если вы хотите проверить, доступна ли эта функция вам, перейдите в раздел «Настройки» и выберите «Попробовать экспериментальные новые функции». В целом, новая функция YouTube представляет собой интересный эксперимент в области улучшения пользовательского опыта. Она может значительно упростить процесс просмотра видео, особенно для тех, кто хочет быстро перейти к самым важным или вирусным моментам. Однако, как и любая новая функция, она требует дальнейшего тестирования и оптимизации, и будет интересно узнать, как она будет принята пользователями и как повлияет на общую стратегию YouTube. В Лос-Анджелесе прошёл фестиваль ИИ-кино — оно уже почти неотличимо от традиционного
04.05.2024 [12:12],
Павел Котов
На этой неделе компания Runway AI, разрабатывающая инструменты для создания и редактирования видео с использованием искусственного интеллекта, провела в Лос-Анджелесе уже второй ИИ-кинофестиваль. В прошлом году участники представили на мероприятии 300 работ. В этом году их стало уже 3000, пишет Bloomberg. 
Источник изображения: openai.com В театре «Орфей» (Orpheum Theatre) собрались кинематографисты, художники, технические специалисты, инвесторы и по крайней мере одна известная актриса — Наташа Лионн (Natasha Lyonne). Они с познакомились с десятью вышедшими в финал работами, которые были отобраны судьями фестиваля. Ленты были довольно странными. В одной из них мультяшная птица киви отправилась в приключение через океан. Другая работа олицетворяла борьбу современного человека с тревожностью — запертый в доме главный герой сражался с мясным монстром. В этом году атмосфера мероприятия была той же, что и в прошлом, зато работы заметно отличались. Они меньше походили на экспериментальное кино и уже больше напоминали традиционное. В прошлом году Runway собиралась представить ПО, позволяющее генерировать видео по текстовому описанию. Тогда кинематографисты лишь начинали задумываться, как ИИ может вписаться в творческий процесс — это могли быть сгенерированные ИИ или созданные Runway инструменты для монтажа. В одной из прошлогодних работ странные расплывчатые лица в кадре, казалось, соответствовали художественному замыслу. Теперь ИИ-ленты преобразились, как и зарождающаяся отрасль, которая их производит. Runway — лишь одна из нескольких компаний, предлагающих генерацию видео по текстовому описанию. Прорыв обещает совершить OpenAI, представившая модель Sora. Официальной даты запуска у неё пока нет, но разработчик предоставил к ней доступ небольшой группе профессионалов, и это дало интересные результаты. ИИ быстро превращается из необычной новинки в полезный инструмент для кинематографистов. Глядя представленные на фестивале работы, не всегда можно было точно сказать, где и как в производственном процессе использовался ИИ. Microsoft закрыла полиции США доступ к ИИ, который использовали для распознавания лиц
03.05.2024 [12:52],
Павел Котов
Microsoft подтвердила запрет полицейским структурам в США использовать инструменты генеративного искусственного интеллекта для распознавания лиц, основанные на технологиях её партнёра OpenAI — корпоративные клиенты могут пользоваться ими в облачной инфраструктуре Azure. 
Источник изображения: Tumisu / pixabay.com В условиях обслуживания платформы Azure OpenAI Service появилась формулировка, которая с большей очевидностью запрещает осуществлять её интеграцию с полицейскими структурами в США с целью распознавания лиц, включая интеграцию с существующими и перспективными моделями ИИ для анализа изображений. Отдельный пункт документа прямо запрещает использование «технологии распознавания лиц в реальном времени» на мобильных камерах, включая нательные камеры и видеорегистраторы для попыток идентификации личности в «неконтролируемых» условиях. Microsoft обновила политику через неделю после того, как компания Axon, производитель технологического оборудования для вооружённых сил и правоохранительных органов, анонсировала новую систему расшифровки записи звука с нательных камер — эта система основана на модели OpenAI GPT-4. Правозащитники указали, что она может давать сбои из-за склонности ИИ к галлюцинациям и расовым предубеждениям. При этом отсутствуют точные сведения, использовала ли Axon доступ к GPT-4 через Azure OpenAI Service, а если да, то стало ли обновление политики реакцией на этот продукт. Запрет на доступ к Azure OpenAI Service распространяется только на полицию США, а не правоохранительные органы других стран. Он также не распространяется на системы распознавания лиц с помощью стационарных камер в контролируемых средах, например, на территории отделения. OpenAI, которая ранее отказывалась от сотрудничества с вооружёнными силами, запустила ряд проектов для Пентагона, в том числе по направлению кибербезопасности, сообщило в январе агентство Bloomberg. Microsoft также предложила Министерству обороны США генератор изображений OpenAI DALL-E для разработки ПО для проведения военных операций, узнало издание The Intercept. Платформа Azure OpenAI Service с дополнительными возможностями стала доступной в пакете Microsoft Azure для государственных учреждений в феврале. Мобильный ИИ-гаджет Rabbit R1 за $199 подвергся критике экспертов после дебюта на CES 2024
02.05.2024 [06:25],
Дмитрий Федоров
Новейший ИИ-гаджет Rabbit R1, вызвавший волну интереса на международной выставке CES 2024, после начала продаж подвергся жёсткой критике со стороны экспертов. Стоимость устройства составляет $199, но ряд технических недочётов и ограниченная функциональность вызвали серьёзные вопросы к его практической ценности. 
Источник изображений: rabbit.tech На CES Rabbit R1 быстро стал центром внимания благодаря своей инновационной системе — большой модели действий (Large Action Model или LAM), которая позволяет устройству автоматически выполнять задачи, аналогично персональному ассистенту. Эта технология предполагает не просто выполнение команд, а обучение в процессе использования, что открывает новые перспективы для взаимодействия пользователя с устройством. Благодаря этому 10 000 устройств были проданы по предварительным заказам.  Однако, вопреки изначальному энтузиазму, в первых обзорах новинки эксперты стали указывать на серьёзные проблемы с совместимостью приложений и недолговечностью батареи. Интересно, но на момент запуска Rabbit R1 поддерживает всего четыре приложения, что значительно ограничивает его функциональность. Продолжительность работы устройства от одного заряда батареи составляет всего несколько часов, что ставит под вопрос его удобство в ежедневном использовании.  Технологический обозреватель Маркес Браунли (Marques Brownlee), известный своей критической оценкой продукта Humane AI Pin, отметил, что хотя Rabbit R1 и лучше, планка для его сравнения установлена довольно низко. Он подчеркнул, что устройство кажется незаконченным и не готовым к массовому выпуску, и считает его едва ли пригодным для обзора. Его замечание отражает общую тенденцию в технологической и игровой индустрии, а теперь и в продуктах с ИИ, которые кажутся сделанными наспех.  Как отмечают издания Tom's Guide и Digital Trends, устройство создаёт впечатление «сырого» продукта. В частности, Tom's Guide присвоил Rabbit R1 оценку в 1,5 звезды из 5 и посоветовал избегать этого гаджета, а Digital Trends назвал новинку «беспорядочной», подчёркивая серьёзные недостатки в её функциональности. Многие рецензенты сомневаются в целесообразности Rabbit R1, тем более что кажется, что всё, что он делает, можно сделать с помощью приложения для смартфона.  Журналист Мишаал Рахман (Mishaal Rahman) из издания Android Authority продемонстрировал, что некоторые функции Rabbit R1 можно реализовать, установив файл APK лаунчера Rabbit на смартфон Google Pixel 6A. Однако он отметил, что без привилегированных разрешений системного уровня не все функции работают должным образом, что свидетельствует о потенциальных ограничениях такой интеграции. Появление Rabbit R1 на рынке стало ярким событием, однако первый опыт эксплуатации оставил пользователей с множеством вопросов и сомнений. Производителю предстоит не только доработать свой продукт до уровня ожиданий пользователей, но и продемонстрировать, что инновации могут быть не только яркими, но и функциональными, чтобы восстановить утраченное доверие. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться